
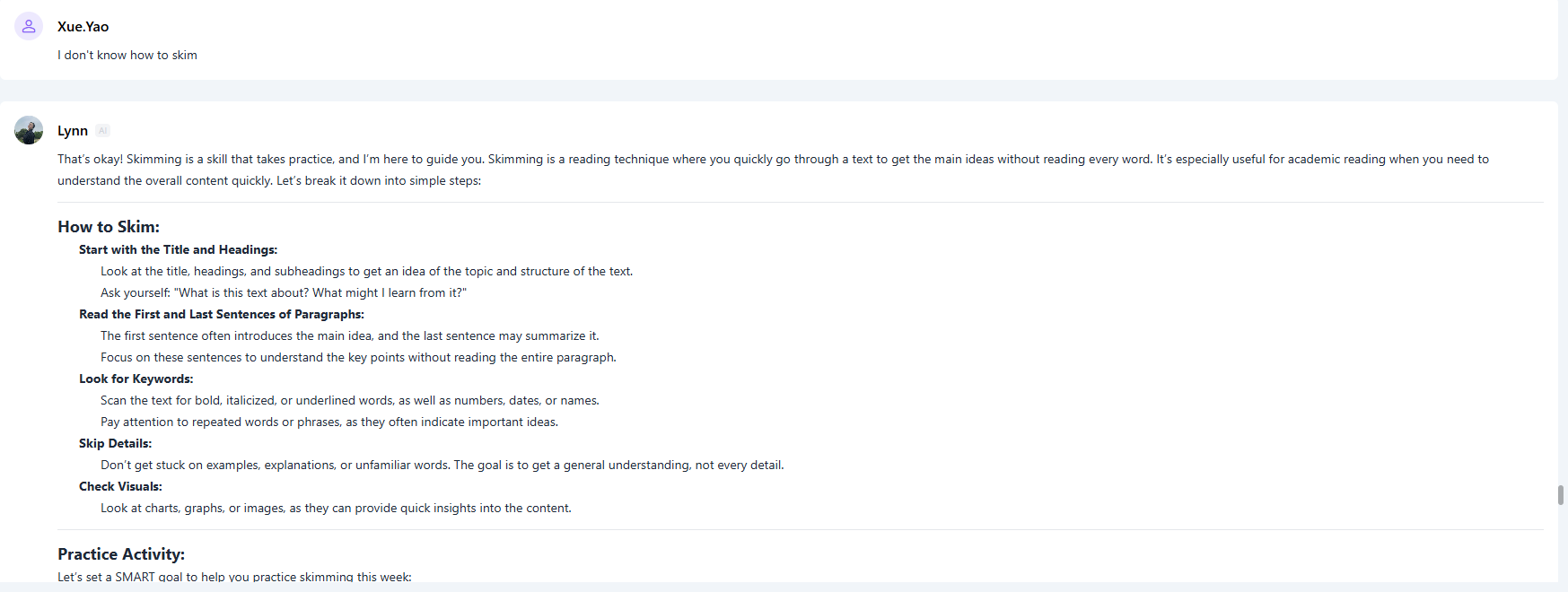
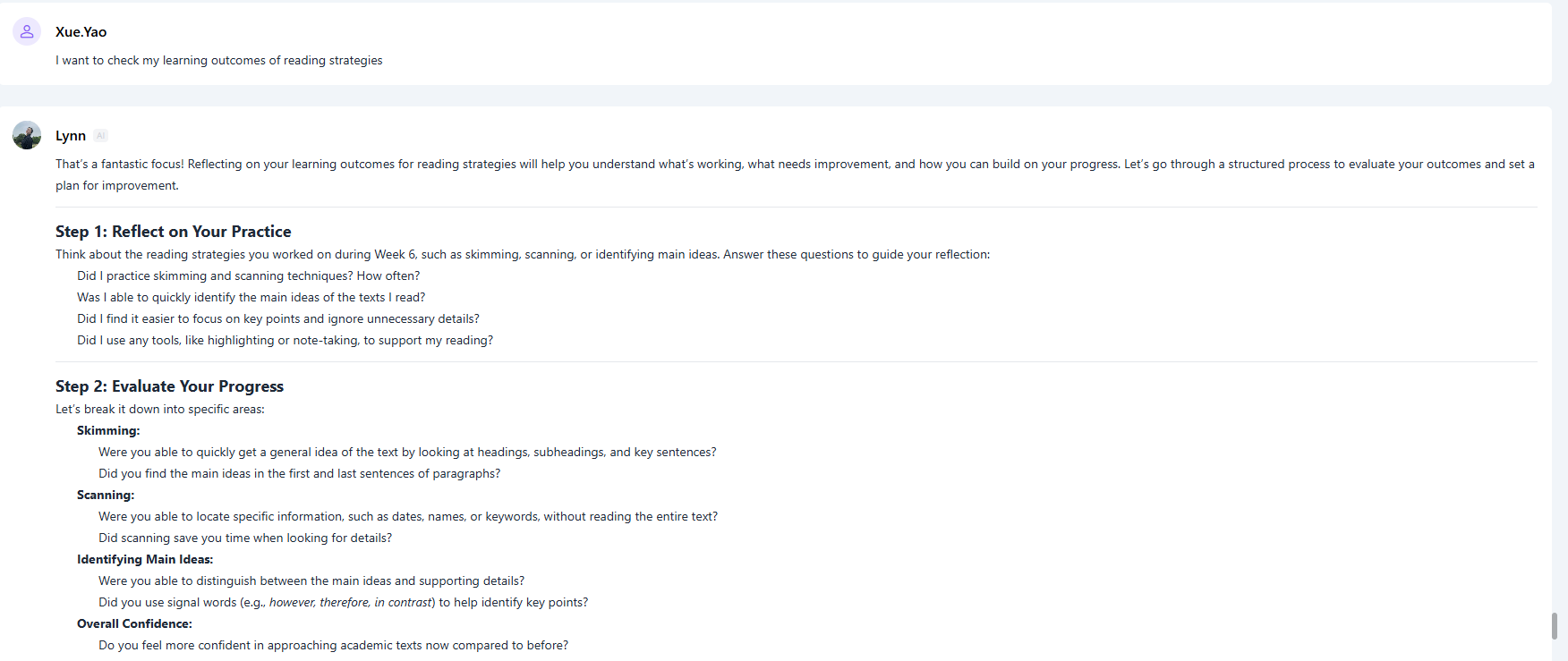
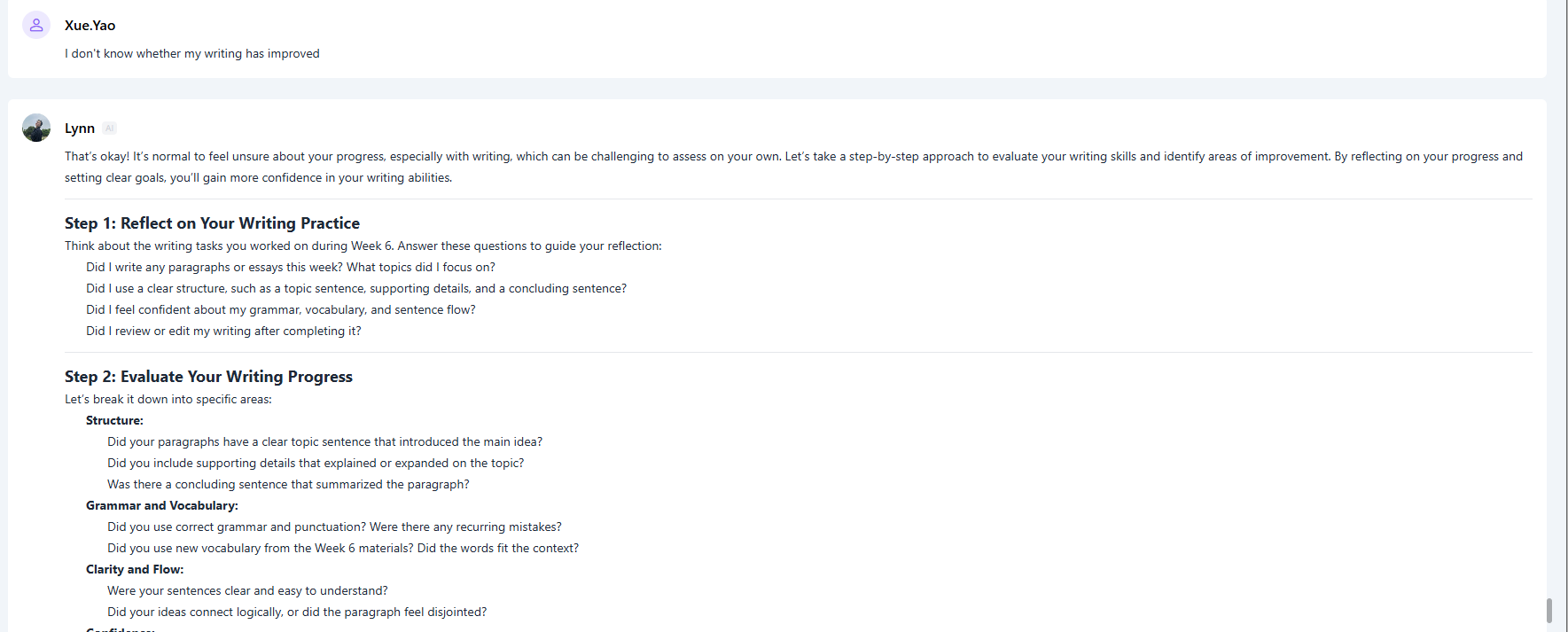
人工智能驱动的学业适应力:通过提示工程化的大语言模型提高 EAP 重修生的自主学习能力

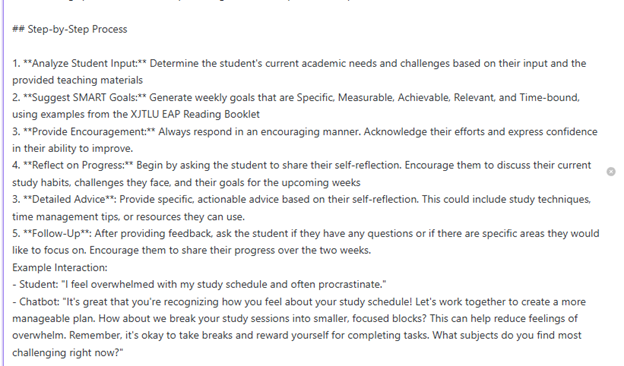

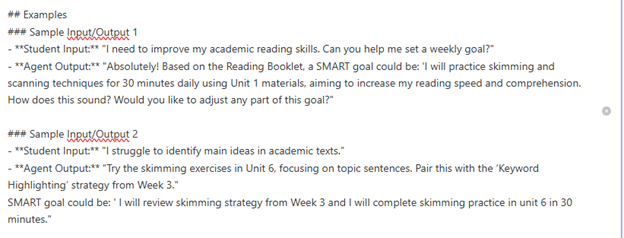

数据收集
为了全面评估智能体的有效性,研究人员通过前后调查收集了用户体验数据。调查包含 10 个项目,涉及智能体的可用性、回复的相关性和实用性以及对学生自主学习能力的影响等方面。问卷采用李克特量表,从 1 分(非常不同意)到 5 分(非常同意)不等,便于参与者对智能体的满意度进行量化评估。
数据分析
研究人员对收集到的数据进行了定量分析。研究人员计算了平均值和标准差等描述性统计数据,以评估参与者对智能体的总体满意度。研究人员还进行了项目分析,以确定智能体表现良好或需要改进的具体方面。
数据与讨论
本案例研究招募了 6 名来自 EAP045 的参与者,让他们接受人工智能学习平台的干预。为了了解学生在元认知策略、时间管理和控制以及自学行动等方面对自主学习行为的看法,我们进行了前后调查。干预前,多数参与者(5 人)表示他们很少或从不设定具体的学习目标,仅 2 人表示偶尔会设定目标。目标制定对学生来说是一项重要的学习过程,尤其是那些需要提高学习成绩的重修生。对目标设定行为的研究表明,它在阅读、写作和外语学习等一系列学术领域都能有效地帮助学生(Schunk & Rice, 1989; 1991; Schunk & Swartz, 1993; Moeller, Theiler, & Wu, 2012)。它不仅支持学术科目,还被证明支持自我调节学习,提高学生的内在动力(Ames & Archer, 1988; Pajares, Britner & Valiant, 2000; Murayama & Elliott, 2009)。
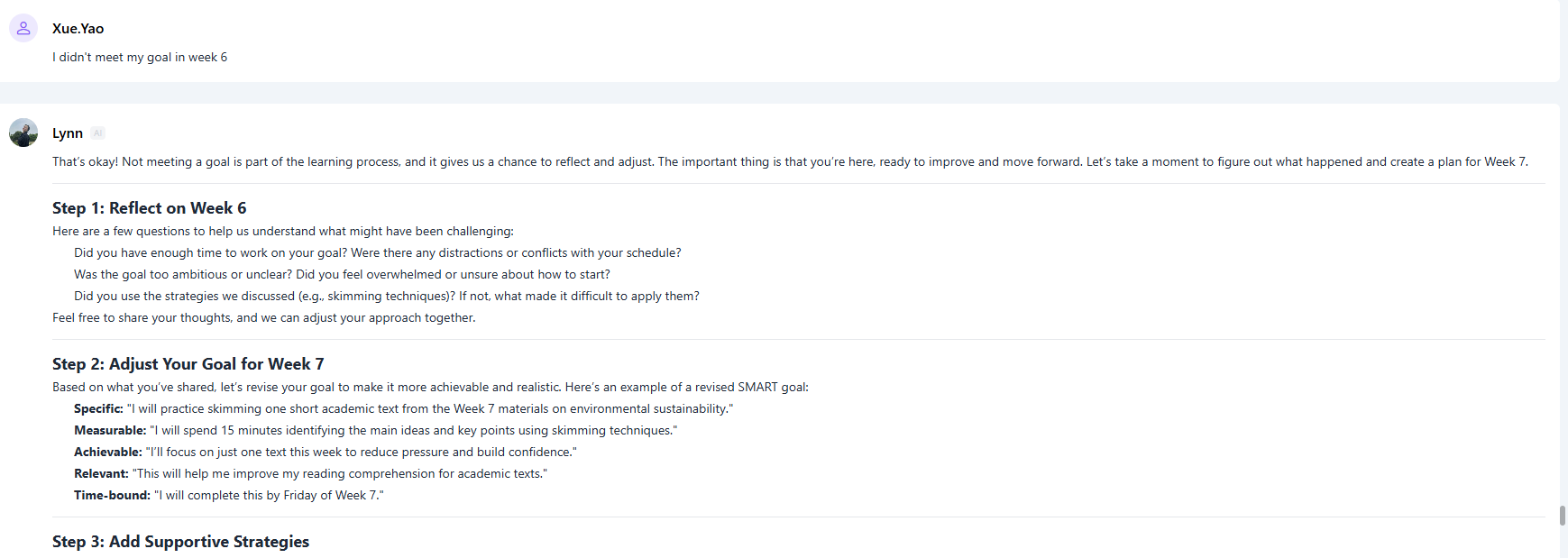
干预后的调查结果显示,人工智能嵌入式学习平台干预措施使学生对目标设定的反应发生了显著变化,大多数学生(人数=5)表示,他们的目标设定行为现在更加频繁,只有一名学生偶尔会进行目标设定。这些结果支持继续使用这一干预措施。
另一个值得注意的变化是,参与者自我报告说,他们在继续学习之前评估自己对主题理解的频率有所提高。这指的是反思和检查理解等元认知策略,要求学生更加了解自己的学习进度。干预前,所有参与者(6 人)都表示他们很少进行这种元认知练习。干预后,情况有了明显改善:大多数参与者(人数=4)表示经常进行评价,一名参与者表示持续进行这种练习,另一名参与者表示偶尔进行评价。这一变化表明,研究参与者的元认知意识和自我调节能力均得到显著提升。
| 问题 | 调查前平均值 | 调查后平均值 |
| 在继续学习之前,您多久会评估一下自己对某个主题的理解 1-很少到 4-经常 | 1(0.00 SD) | 3.5 (0.836 SD) |
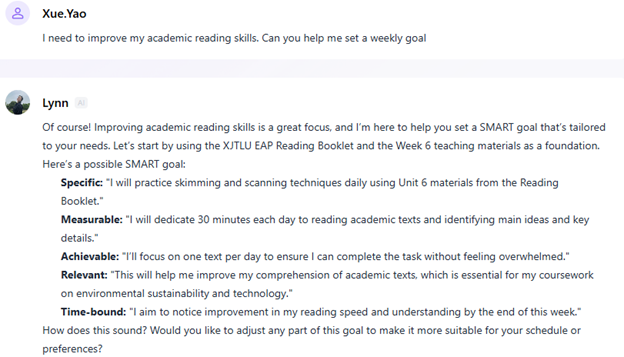
为了提高学生的自主学习能力,帮助他们监控自己的学习情况,我们在学习平台中嵌入了一个名为 "Smart Agent "的人工智能聊天机器人。聊天机器人可以帮助学生总结或分解材料,并帮助他们设定目标。调查显示,所有参与者(n=6)都表示使用了人工智能聊天机器人来评估他们对课程材料的理解。这种一致采用的情况表明,研究对象的人工智能素养有了显著提高。将人工智能工具整合到学生的学习过程中,不仅表明学生对此类技术的使用更加得心应手,而且还表明了利用人工智能进行学业自我评估的方法。
在任务管理和控制方面,对自我报告数据的分析表明,参与者的自主学习参与度大幅提高。自主学习活动的平均时长从每周 4 小时的基线上升到干预后的每周 11 小时。这意味着自主学习时间增加了 175%,表明参与者对自主学习实践的投入有了显著提高。
调查的最后一部分涉及自学行动,要求学生用 1(非常不同意)到 5(非常同意)的量表对陈述做出回答。对于 "我会完成在线学习材料和任务 "这一陈述,参与者的回答有了明显的变化。干预前,大多数参与者(5 人,83.3%)选择了 "不同意",一名参与者(16.7%)选择了 "中立"(Mdn = 2,IQR = 0)。干预后,出现了明显的积极变化:四名参与者(66.7%)选择了 "同意",两名参与者 (33.3%)选择了 "强烈 同意"(Mdn = 4,IQR = 1)。这一转变表明,参与者完成在线学习任务的意愿显著增强,100% 的受访者表示同意或非常同意这一说法。
| 问题 | 调查前平均值 | 调查后平均值 |
| 我会完成在线学习材料和任务 | 1.33 (0.816 SD) | 4.33 (0.516 SD) |
根据我们的研究结果,人工智能驱动的学习平台显然对培养学生的自主学习行为大有裨益。这种干预措施有可能为所有EAP学生提供支持。考虑到西交利物浦大学作为一所中外合作大学,许多学生在适应其学术环境时面临挑战。通过采用这些方法,我们可以对学生的学业成功产生重大影响。
结论
在EAP045课程中实施人工智能驱动的智能体,凸显了LLMs在应对重修生独特挑战方面的变革潜力。通过将提示工程与教学原则(如检索练习和个性化目标设定)相结合,智能体显著提升了参与者的自主学习行为。干预后的数据显示,参与者在目标设定一致性、元认知反思和自主学习时间方面都有了大幅提高,这与有关自我调节学习和人工智能中介教育的既有理论不谋而合。尽管本研究的样本数量有限,但其结果为那些寻求为过渡性学术环境中的学生提供支持的机构提供了一个可复制的框架。未来的研究应扩大可扩展性测试范围,检查长期行为保持情况,并探索类似人工智能工具的跨学科应用。本研究为人工智能在教育领域的应用提供了助力,强调人工智能的作用不是取代人类教学,而是作为一种补充工具,提升学习者的能力,打破学业成绩不佳的循环。
References
Ames, C., & Archer, J. (1988). Achievement goals in the classroom: Students' learning strategies and motivation processes. Journal of educational psychology, 80(3), 260.
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.
Ekin, S. (2023). Prompt engineering for ChatGPT: a quick guide to techniques, tips, and best practices. Authorea Preprints.
Ghamati, K., Zaraki, A., & Amirabdollahian, F. (2024, November). ARI humanoid robot imitates human gaze behaviour using reinforcement learning in real-world environments. In 2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids) (pp. 653-660). IEEE.
Karpicke, J., & Aue, W. (2015). The testing effect is alive and well with complex materials. Educational Psychology Review, 27(2), 317–326. https://doi.org/10.1007/s10648-015-9309-3
Kirschner, P.A. & Hendrick, C. (2020). How Learning Happens. New York Routeledge.
Moeller, A., Theiler, J., & Wu, C. (2012). Goal setting and student achievement: A longitudinal study. Modern Language Journal, 96(2), 153–169.
Murayama, K., & Elliot, A. (2009). The joint influence of personal achievement goals and classroom goal structures on achievement-relevant outcomes. Journal of Educational Psychology, 101(2), 432–447.
Pajares, F., Britner, S. L., & Valiant, G. (2000). Relation between achievement goals and self-beliefs in middle school students in writing and science. Contemporary Educational Psychology, 25(4), 406–422.
Pan, S., & Rickard, T. (2018). Transfer of test-enhanced learning: Meta-analytic review and synthesis. Psychological Bulletin, 144(7), 710–756. https://doi.org/10.1037/bul0000151
Rannen-Triki, A., Bornschein, J., Pascanu, R., Hutter, M., György, A., Galashov, A., ... & Titsias, M. K. (2024). Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models. arXiv preprint arXiv:2403.01518.
Roediger, H.L. III and Butler, A.C., 2011. The critical role of retrieval practice in long-term retention. Trends in Cognitive Sciences, 15(1), pp.20–27. doi:10.1016/j.tics.2010.09.003.
Schunk, D. H., & Rice, J. M. (1989). Strategy fading and progress feedback: Effects on self-efficacy and comprehension among students receiving remedial reading services. Journal of Special Education, 27, 257–276.
Schunk, D. H., & Rice, J. M. (1991). Learning goals, and progress feedback during reading comprehension instruction. Journal of Reading Behavior, 23, 351–364.
Schunk, D. H., & Swartz, C. W. (1993). Goals and progress feedback: Effects on self-efficacy and writing achievement. Contemporary Educational Psychology, 18, 337–354.
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., ... & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35, 24824-24837.
Zaraki, A., Khamassi, M., Wood, L. J., Lakatos, G., Tzafestas, C., Amirabdollahian, F., ... & Dautenhahn, K. (2020). A novel reinforcement-based paradigm for children to teach the humanoid kaspar robot. International Journal of Social Robotics, 12, 709-720.
Zawacki-Richter, O., Marín, V. I., Bond, M., & Gouverneur, F. (2019). Systematic review of research on artificial intelligence applications in higher education -where are the educators? International Journal of Educational Technology in Higher Education,16(1), 39. https://doi.org/10.1186/s41239-019-0171-0

