Abstract
First-year EAP programs for advanced English learners face a critical "feedback gap," where high student-to-teacher ratios prevent timely, substantive writing feedback. Consequently, students often turn to generic AI tools, which may provide feedback misaligned with course criteria. This problem is further compounded by many students' lack of skills for effective self-review, ultimately hindering their learning progress and writing development. This article proposes a pedagogical solution: ArgueWell, a multi-agent AI system designed using the XIPU AI platform. The system provides rubric-based feedback, targeted skill practice, and revision tracking to scaffold the self-review process. The article concludes that a pedagogically-grounded, multi-agent AI system can effectively supplement teacher instruction, mitigate the feedback gap, and promote student autonomy in academic writing.
Keywords
Feedback, Generative AI, English for Academic Purposes (EAP), Argumentative Writing, Self-Regulated Learning, Automated Writing Evaluation
1.Introduction
The provision of timely and substantive feedback is a cornerstone of effective writing instruction, particularly in English for Academic Purposes (EAP) contexts. However, a significant challenge arises in high-volume teaching scenarios. For instance, first-year advanced EAP students at XJTLU are required to write an argumentative paragraph or essay every week in the first half of the semester, yet their teachers struggle to provide the necessary feedback given the scale of instruction as each teacher often handles 70-100 students. This situation creates a critical feedback gap, where the demand for quality feedback far outstrips the instructor's capacity to supply it. This challenge is intensified by the high stakes of argumentative writing, which constitutes a substantial portion of the module grade, making accurate and pedagogically grounded support essential.
In the absence of sufficient teacher feedback, a growing number of students intuitively turn to generic generative AI tools like Doubao or Deepseek. While this demonstrates initiative, it introduces a new set of problems. As research on both older Automated Writing Evaluation (AWE) systems and contemporary large language models indicates, such tools often provide feedback that is overly general, linguistically inappropriate for the academic context, and disconnected from specific task requirements (Mau & Feng, 2025). Consequently, students can be misled by AI-generated suggestions that are contradictory to the module's explicit assessment criteria. This not only fosters misunderstanding but also severely limits students' capacity to revise their work effectively and develop as academic writers.
Simultaneously, an increasing cohort of advanced and motivated EAP students are keen to engage in self-directed learning. However, many lack the specific procedural knowledge required to conduct a meaningful self-review of their writing. Effective self-review is not an innate skill but a learned process that involves critical metacognitive strategies (Ratnayake et al., 2024). Students often struggle because they do not know how to systematically deconstruct assessment criteria, apply them objectively to their own work, or formulate a concrete plan for revision (Andrade, 2010; Harris & Brown, 2018). Simply possessing a rubric is insufficient; without explicit training or pedagogical intervention in the steps of self-assessment, such as understanding rubric criteria, diagnosing the root causes of weaknesses, and prioritizing specific areas for improvement, students' self-reviews remain superficial and inaccurate (Al-Nafjan et al., 2025).Therefore, there is a pressing need to explore solutions that can mitigate teacher workload while providing students with reliable, context-specific feedback that aligns with pedagogical principles and empowers autonomous learning.
2.Literature Review
2.1. The Feedback Challenge in EAP and the Promise and Peril of Automated Tools
The challenge of providing timely, detailed feedback in large writing classes is well-documented (Blair, 2017; Shi, 2019; William, 2024). In EAP contexts, where writing is both a core skill and a primary assessment method, this challenge directly impedes student development. Instructors face unsustainable workloads, leading to delayed or less substantive feedback that fails to support the iterative writing process (Haughney et al., 2020). This context has historically driven interest in Automated Writing Evaluation (AWE). Early AWE systems (e.g., Criterion, MY Access!) demonstrated potential for scalability by providing immediate, rule-based feedback on surface-level features like grammar and mechanics (Du & Nordin, 2025; Saricaoglu & Bilki, 2021). However, they were frequently criticized for their limited ability to evaluate higher-order concerns such as argumentation, coherence, and rhetorical effectiveness (Barrot, 2021). Their feedback could be generic, formulaic, and detached from specific assignment prompts, limiting its pedagogical value.
The advent of generative AI and Large Language Models (LLMs) like GPT-4 has renewed interest in automated writing feedback. These tools can generate text and feedback that is more fluent and contextually aware than earlier AWE systems (Lee & Moore, 2024). However, without deliberate instructional design, this feedback can be pedagogically misaligned. It may prioritize linguistic fluency over rubric specific criteria and academic conventions, which risks misleading students and reinforcing student misconceptions rather than supporting learning (Jovic et al., 2025; Irvin et al., 2021). This underscores the necessity of AI tools that are pedagogically engineered and grounded in curriculum and assessment frameworks. Such alignment is especially critical for argumentative writing, which requires evaluating reasoning, evidence, counterarguments, and coherence (Hillocks, 2011).
2.2. Self-Regulated Learning and the Scaffolding of Self-Review
Addressing the feedback challenge is not solely about providing more feedback; it is about enabling students to use feedback effectively to become autonomous writers. This is the domain of self-regulated learning (SRL), where learners actively monitor and manage their own cognitive and metacognitive processes (Zimmerman, 2002). A core component of SRL in writing is effective self-assessment and revision. However, as Andrade (2010) and Yang et al. (2025) systematically review, students, especially those with limited assessment knowledge are often poor self-assessors, struggling to apply criteria accurately to their own work. This is not due to a lack of rubrics but a lack of procedural knowledge—the "know-how" of self-evaluation (Panadero & Jonsson, 2013).
Effective self-review must be explicitly scaffolded. According to Nicol and Macfarlane-Dick’s (2006) formative assessment framework, good feedback should empower students as self-regulators. This involves designing feedback that helps students: 1) understand the goal (e.g., the rubric criteria), 2) compare their current performance against that goal, and 3) take action to close the gap. This process requires more than a single evaluative comment; it requires structured guidance that breaks down the complex task of revision into manageable steps. Research suggests that feedback is most effective when it is task-specific, includes concrete strategies for improvement, and is followed by opportunities for practice and re-evaluation (Hattie & Timperley, 2007). This creates a feedback loop where students can see the impact of their revisions, building self-efficacy and metacognitive awareness.
2.3. Multi-Agent AI for Pedagogically Aligned Formative Feedback
Recent research suggests that multi�agent AI systems can enhance the responsiveness and pedagogical quality of automated feedback, making it more aligned with learning outcomes than traditional single�agent generative models. For example, AutoFeedback (Guo et al., 2024) uses separate agents to generate and validate feedback, reducing errors like over-praise and over-inference. Role-based multi-agent systems (Zhang & Luo, 2025) coordinate evaluator, equity, and metacognitive agents to produce expert-level, pedagogically meaningful feedback that guides students in planning and revising their work. Moreover, multi-agent environments can foster differentiated engagement and learning gains, particularly for learners with lower prior knowledge, by scaffolding interactions that help students interpret feedback, monitor progress, and revise effectively (Hao et al., 2026). In this way, multi-agent AI bridges the gap between automated feedback and pedagogical guidance, supporting the development of autonomous, self-regulated writers.
3. Method
The literature above points to a clear convergence of needs and technological possibilities. This section introduces ArgueWell (https://aiagent.xjtlu.edu.cn/product/llm/mall/application/d3vekc16i3uelisj4u0g/chat ), a self-designed, multi-agent AI system developed to tackle three interconnected challenges: the challenge of providing feedback that is both timely and scalable, the limitations of generic AI tools, and students’ underdeveloped self-review skills, as identified in the introduction. The primary goal of this methodological phase was to create a pedagogically grounded technological intervention that could be iteratively refined.
The development process focused on three core principles: (1) embedding a high-quality feedback framework for general feedback into the system's architecture, (2) ensuring all feedback was explicitly tied to the module's specific assessment criteria, and (3) scaffolding the student's journey from feedback reception to independent revision and self-evaluation.
3.1. System Architecture and Platform
The ArgueWell system was prototyped using the XIPU AI Agent Platform, a development environment chosen for its modular agent architecture, integrated knowledge base functionality, and robust workflow design capabilities. This platform enabled the creation of a sequenced, task-oriented tutoring system that simulates the structured support of an expert writing tutor. The project involved the design and integration of three specialized AI agents—an Overall Assessor, a Targeted Writing Coach, and a Revision Evaluator—each with a distinct role in the student's writing process. This multi-agent design was a direct response to the limitations of monolithic, generic AI tools (Barrot, 2021), ensuring that feedback was not a single, overwhelming output but a structured, multi-stage learning dialogue.
3.2. Knowledge Base Construction
The foundation of the system's pedagogical validity is its custom-built Knowledge Base (KB). To directly combat the problem of AI feedback being "disconnected from specific task requirements" (Mau & Feng, 2025), the KB was populated exclusively with module-specific materials from EAP047. The core component is the EAP047 analytic writing rubric, which was deconstructed into its constituent parts:
· Task: Including word count, idea relevance, idea development and critical reasoning.
· Organization: Encompassing paragraph structure, cohesion, transitions, and overall logical flow.
· Vocabulary: Focusing on academic register, precision, and lexical variety.
· Grammar: Covering accuracy, sentence structure, and grammatical range.
This rubric-centric approach ensures that every piece of feedback generated by the AI agents is criterion-referenced, thereby aligning the technology's output directly with the module's learning outcomes and assessment standards.
3.3. Agent Design Logic and Pedagogical Rationale
The three agents operate in a fixed sequence, guiding the student through a coherent learning cycle modelled on the principles of effective formative assessment set forth by Nicol and Macfarlane-Dick (2006). This design explicitly aims to develop the "procedural knowledge" for self-review that students currently lack (Andrade, 2010; Panadero & Jonsson, 2013). Each agent ends with a question or an instruction, and a positive response such as “yes” or “ok” initiates the next stage. For example, Agent 1 ends with, “Do you want an overall score and subscores based on the writing descriptor.pdf?” A positive answer leads to a detailed breakdown of the score across the four criteria, followed by the question, “Do you want to know your weakest area?” A “yes” response triggers Agent 2, and a subsequent action of uploading a revised essay to “Please upload your revised essay so that I can evaluate your progress and provide a detailed report.” triggers Agent 3.
3.3.1. Agent 1: The Overall Assessor
The first agent in the sequence is designed to replicate the initial, holistic feedback a teacher might provide, but with consistency and immediate turnaround. Its primary function is to conduct a comprehensive evaluation of the submitted essay against the four rubric criteria (See Figure 1).
The feedback generated by Agent 1 is structured according to a high-quality feedback framework synthesised from empirical studies (Patchan et al., 2016; Wu & Schunn, 2021). This ensures the feedback is pedagogically substantive and not merely corrective. The framework mandates that feedback contains:
1.Affective Elements: The inclusion of balanced praise to acknowledge strengths and maintain student motivation, countering the purely transactional tone of generic AI.
2.Description: A concise summary statement demonstrating the AI's understanding of the essay's content and argument, validating the student's effort.
3.Identification: Clear pinpointing and localization of specific issues (e.g., "The topic sentence in your second paragraph is too broad").
4.Justification: An explanation of why the identified issue matters, explicitly linking it back to the rubric criteria (e.g., "This weakens the Organization criterion because it makes the paragraph's focus unclear to the reader").
5.Constructive Guidance: Actionable, specific recommendations for improvement (e.g., "Try revising the topic sentence to make a more specific, debatable claim that your paragraph will then prove.").
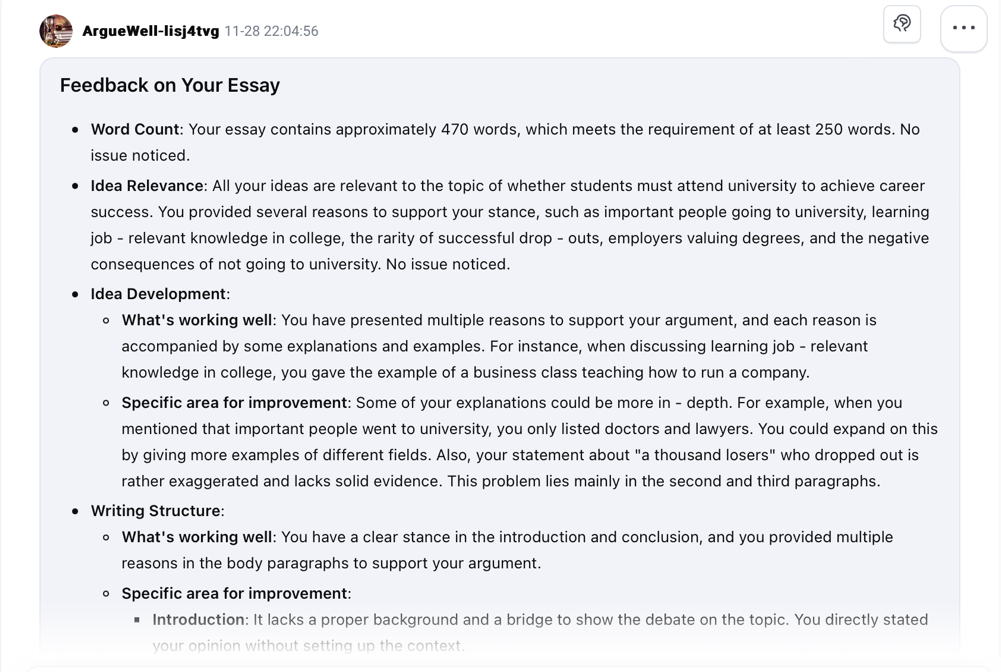
Figure 1. Sample feedback generated by Agent 1 aligned with the EAP047 marking descriptor and the feedback framework.
Finally, when asked, Agent 1 provides a total score and subscores for each criterion, with each score explicitly justified by reference to the marking descriptor (See Figure 2). This transparent scoring demystifies the assessment process for students, directly addressing the problem of them not knowing how to deconstruct, interpret and operationalise assessment criteria (Andrade, 2010; Harris & Brown, 2018).
Figure 2. Subscores generated by Agent 1 based on the EAP047 marking descriptor.
3.3.2. Agent 2: The Targeted Writing Coach
Following the overall assessment, Agent 2 addresses the issue of cognitive overload and the need for targeted skill development. Instead of overwhelming the student with all possible areas for improvement, this agent analytically identifies the single weakest criterion based on the subscores from Agent 1 (See Figure 3). This focused approach is a direct pedagogical choice to facilitate deeper learning.
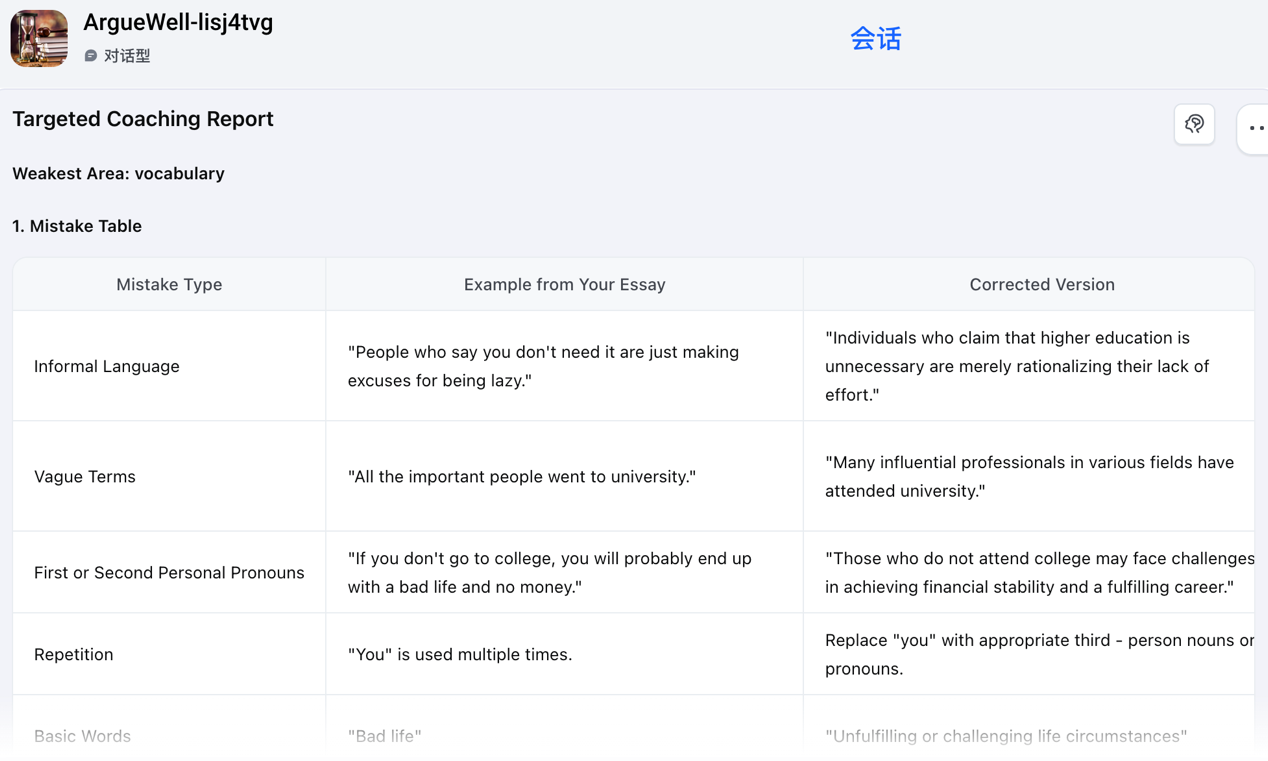
Figure 3. The weakest criterion identified by Agent 2 based on subscores generated by Agent 1.
The agent then functions as a remedial tutor, generating personalised micro-lessons and practice tasks based on the student's own writing (See Figure 4). For instance, if “Vocabulary” is identified as the weakest area, the agent might isolate a sentence containing informal expressions and prompt the student to: “Rewrite the informal words or phrases in this sentence with more formal, academic alternatives.” Crucially, the agent also provides a model answer, allowing students to compare their response against a benchmark. The exercises follow Bloom’s Taxonomy, progressing from lower-order to higher-order thinking skills, for example, starting with identifying mistakes in a sentence, then rewriting a problematic sentence to remove issues, and finally creating a new sentence. This structured approach actively engages students in targeted practice, scaffolding the ability to diagnose and address their own weaknesses.
 Figure 4. Practice tasks generated by Agent 2 based on the student’s own writing, focusing on the weakest criterion.
Figure 4. Practice tasks generated by Agent 2 based on the student’s own writing, focusing on the weakest criterion.
3.3.3. Agent 3: The Revision Evaluator
The final agent in the sequence is dedicated to fostering metacognition and closing the feedback loop. After the student has engaged with the feedback from Agents 1 and 2 and revised their essay, they submit the new draft to Agent 3. This agent does not simply re-grade the work; it performs a comparative analysis (See Figure 5).
Agent 3 generates a "progress report" that:
· Compares the old and new scores across all criteria.
· Offers a detailed analysis of what improvements were made, providing evidence from the revised text.
· Highlights areas that still require work, offering further constructive guidance.
· Suggests concrete next steps for continuous improvement.
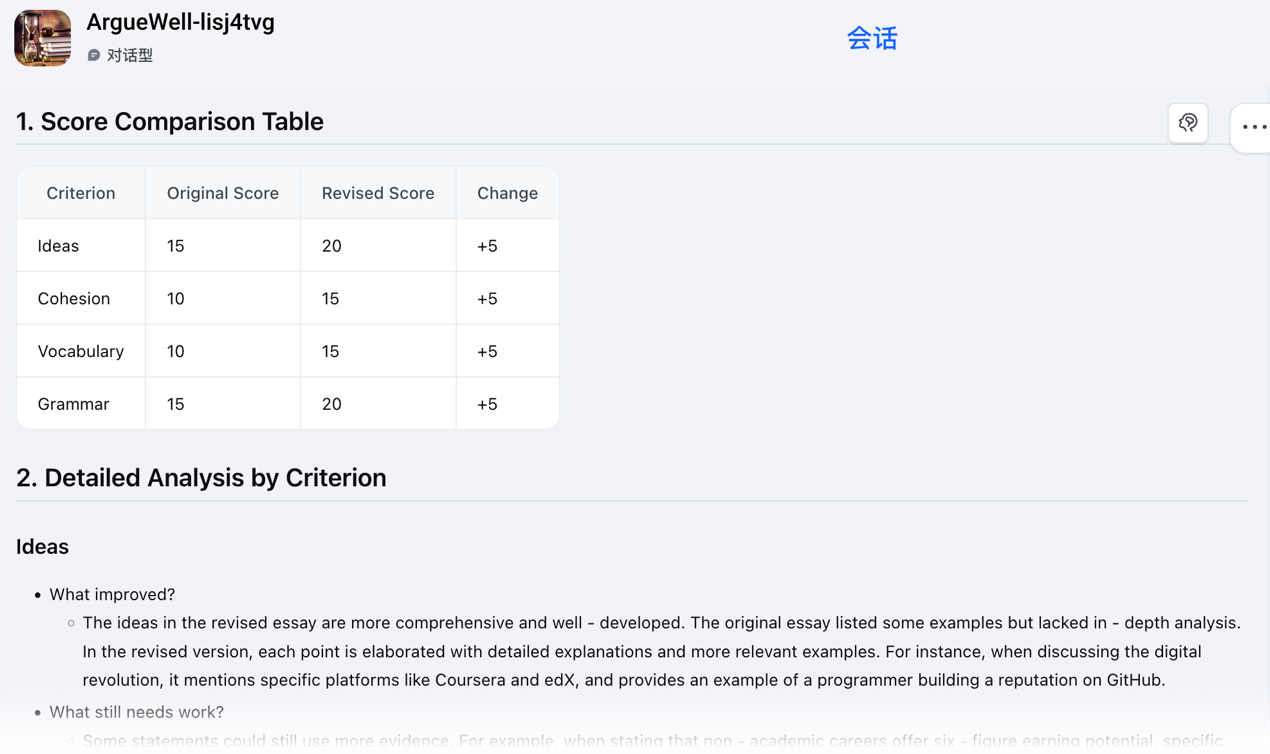
Figure 5. Example of a student progress report generated by Agent 3.
This function is critical for teaching students how to formulate a concrete plan for revision and reflect on their progress (Nicol and Macfarlane-Dick, 2006). By making improvement visible and tangible, the Revision Evaluator empowers students to see the direct results of their revision efforts, thereby building self-efficacy and reinforcing the value of the self-review process.
3.4. Technical Workflow and Scaffolding
The user journey through ArgueWell is a linear, scaffolded process:
1.Upload: Student submits their argumentative essay.
2.Assess: Agent 1 provides a holistic, rubric-based evaluation.
3.Coach: Agent 2 identifies the weakest area and delivers targeted practice.
4.Revise & Re-submit: The student revises their essay based on the accumulated insights.
5.Evaluate: Agent 3 assesses the revision and produces a progress report.
3.5. Potential Challenges and Mitigation Strategies for the Three-Agent AI System
While the three-agent system offers scaffolded, personalized support, several potential challenges may arise. First, misalignment with rubric criteria or incorrect identification of the weakest area could lead to misleading feedback; this can be mitigated through periodic human calibration and integrating multiple validation checks across agents. Second, students may experience cognitive overload if too many prompts or tasks are presented sequentially; adaptive pacing and limiting the number of tasks per session can help manage workload. Third, over-reliance on AI guidance may hinder the development of independent self-regulation; embedding reflective questions and requiring students to justify their revisions encourages metacognitive engagement. By combining careful calibration, adaptive task design, and scaffolds for autonomy, these risks can be minimized while maintaining pedagogical effectiveness.
4. Conclusion
The ArgueWell system demonstrates a viable path to addressing the critical challenges of feedback scalability, unreliable generic AI, and underdeveloped self-review in EAP writing. By embedding a structured, multi-agent process that provides criterion-referenced feedback, targeted practice, and progress tracking, the tool effectively bridges the feedback gap. Notably, the system scaffolds the metacognitive process of self-review, empowering students to become more autonomous writers. This project affirms that pedagogically-grounded AI, designed as a force multiplier rather than a teacher replacement, can create a more sustainable and effective learning ecosystem, fostering both improved writing outcomes and essential self-regulated learning skills. Future work will focus on longitudinal studies to quantify its long-term impact.
References
Andrade, H. L. (2010). Students as the definitive source of formative assessment: Academic self-assessment and the self-regulation of learning. In Handbook of Formative Assessment (pp. 90–105).
Al-Nafjan, E., Alhawsawi, S., & Abu Dujayn, A. N. (2025). Exploring self-assessment in EFL academic writing: A study of undergraduate Saudi students utilizing a rubric. Language Testing in Asia, 15, 62.
https://doi.org/10.1186/s40468-025-00397-2Blair, A. (2017). Understanding first-year students’ transition to university: A pilot study with implications for student engagement, assessment, and feedback. Politics, 37(2), 215–228.
https://doi.org/10.1177/0263395716633904Du, J., & Nordin, N. R. binti M. (2025). A systematic review of Automated Writing Evaluation (AWE) systems on university students’ English writing performance. Forum for Linguistic Studies, 7(11), 615–.
https://doi.org/10.30564/fls.v7i11.11764Guo, S., Latif, E., Zhou, Y., Huang, X., & Zhai, X. (2024). Using generative AI and multi-agents to provide automatic feedback. arXiv.
https://arxiv.org/abs/2411.07407Hao, Z., Cao, J., Li, R., Yu, J., Liu, Z., & Zhang, Y. (2026). Mapping student-AI interaction dynamics in multi-agent learning environments: Supporting personalized learning and reducing performance gaps. Computers & Education, 241, 105472.
https://doi.org/10.1016/j.compedu.2025.105472
Harris, L. R., & Brown, G. T. (2018). Using self-assessment to improve student learning. Routledge.
Hillocks, G. (2011). Teaching argument writing, grades 6–12. Heinemann.
Irvin, M. K., Asaba, M., Stegall, J., Frank, M., & Gweon, H. (2021). “This one’s great! That one’s okay.”: Investigating the role of selective vs. indiscriminate praise on children’s learning behaviors. The Undergraduate Research Journal of Psychology at UCLA, 8, 50–82.
Jovic, M., Papakonstantinidis, S., & Kirkpatrick, R. (2025). From red ink to algorithms: Investigating the use of large language models in academic writing feedback. Language Testing in Asia, 15, 59.
https://doi.org/10.1186/s40468-025-00389-2Lee, S. S., & Moore, R. L. (2024). Harnessing generative AI (GenAI) for automated feedback in higher education: A systematic review. Online Learning, 28(3), 82–104.
https://doi.org/10.24059/olj.v28i3.4593Mau, B.-R., & Feng, H.-H. (2025). Integrating move analysis and sentence reconstruction in automated writing evaluation for L2 academic writers. Assessing Writing, 66, 100984.
https://doi.org/10.1016/j.asw.2025.100984Nicol, D. J., & Macfarlane-Dick, D. (2006). Formative assessment and self-regulated learning: A model and seven principles of good feedback practice. Studies in Higher Education, 31(2), 199–218.
https://doi.org/10.1080/03075070600572090Panadero, E., Jonsson, A., & Strijbos, J. W. (2016). Scaffolding self-regulated learning through self-assessment and peer assessment: Guidelines for classroom implementation. In D. Laveault & L. Allal (Eds.), Assessment for Learning: Meeting the Challenge of Implementation (pp. 311–326). Springer International Publishing.
https://doi.org/10.1007/978-3-319-39211-0_18Patchan, M. M., Schunn, C. D., & Correnti, R. J. (2016). The nature of feedback: How peer feedback features affect students' implementation rate and quality of revisions. Journal of Educational Psychology, 108(8), 1098–1120.
https://doi.org/10.1037/edu0000103Ratnayake, A., Bansal, A., Wong, N., Saseetharan, T., Prompiengchai, S., Jenne, A., Thiagavel, J., & Ashok, A. (2024). All “wrapped” up in reflection: Supporting metacognitive awareness to promote students' self-regulated learning. Journal of Microbiology and Biology Education, 24(1), e00103-23.
https://doi.org/10.1128/jmbe.00103-23Shi, M. (2019). The effects of class size and instructional technology on student learning performance. The International Journal of Management Education, 17(1), 130–138.
https://doi.org/10.1016/j.ijme.2019.01.004Williams, A. (2024). Delivering effective student feedback in higher education: An evaluation of the challenges and best practice. International Journal of Research in Education and Science (IJRES), 10(2), 473–501.
https://doi.org/10.46328/ijres.3404Wu, Y., & Schunn, C. D. (2021). From plans to actions: A process model for why feedback features influence feedback implementation. Instructional Science, 49(3), 365–394.
https://doi.org/10.1007/s11251-021-09546-5Yang, M., Yan, Z., Yang, L., & Zhan, Y. (2025). Using self-assessment to develop student assessment literacy. In Understanding and Developing Student Assessment Literacy (Springer Briefs in Education). Springer, Singapore.
https://doi.org/10.1007/978-981-97-9484-3_3Zhang, C., & Luo, X. (2025). Scaling equitable reflection assessment in education via large language models and role-based feedback agents. arXiv.
https://arxiv.org/abs/2511.11772
Zimmerman, B. J. (2002). Becoming a self-regulated learner: An overview. Theory into Practice, 41, 64–70. https://doi.org/10.1207/s15430421tip4102_2



