
Beyond Pre-Listening: Implementing Spontaneous Prediction Activities in the L2 Classroom
Spontaneous prediction, also referred to as real-time or on-line prediction, plays a central role in efficient spoken language comprehension, yet it remains underdeveloped in many L2 listening classrooms. While traditional pre-listening activities support macro-level topic activation, they offer limited support for the rapid, subconscious prediction required in authentic academic listening. To address this gap, the paper presents a classroom-based pedagogical framework that explicitly trains spontaneous prediction across three cognitive layers: semantic–discourse, syntactic, and phonological. Using a reverse-sequenced instructional design, the study illustrates three teaching practices implemented in an ESAP context: a discourse-level “Cliffhanger” activity targeting stance and logical forecasting, a phonological “Phonetic Forecasting” technique employing acoustic filtering to enhance prosodic sensitivity, and a syntactic “Grammar GPS” approach that leverages structural expectations to reduce processing load.
Key Words:
Spontaneous prediction, L2 listening, predictive processing, cognitive load
In the context of language learning, spontaneous prediction, sometimes called "on-line" or "real-time" prediction, is the brain's subconscious ability to anticipate the next word, sound, or idea while speech is unfolding (Field, 2008). Unlike traditional "pre-listening" exercises, where a teacher might ask a student to look at a picture and guess a topic before pressing play, spontaneous prediction is constant, rapid, and automatic. In essence, the brain does not simply sit and wait for sound to hit ears; instead, it acts as a "prediction engine" (Field, 2008; Bar, 2009). As we listen, our mind uses every available bit of data to narrow down what is likely to come next.
This engine operates across three distinct cognitive layers, allowing us to process language before it is even fully uttered (Field, 2008). At the phonological level, the brain engages in rapid pattern matching; for example, hearing a partial sound like "pro-b..." triggers an immediate lean toward likely completions such as "probably" or "problem." At the syntactic level, the mind utilizes grammatical constraints to "pre-fill" upcoming slots, such as automatically expecting a noun like "mat" or "floor" when a speaker begins, "The cat sat on the..." Finally, at the semantic and discourse level, the listener uses logic and transition markers to forecast the speaker's intent (Field, 2008). This is most evident in complex listening where a phrase like "I love the city, however..." signals the brain to prepare for a contrasting stance or a negative point before the speaker even articulates it.
However, for many L2 (second language) learners, a persistent "listening gap" occurs because this spontaneous prediction is either delayed or absent. In a native language, this process happens so fast it feels like listeners are "reading the speaker's mind," which significantly reduces the effort the brain has to make. In a foreign language, however, students often become trapped in a labor-intensive "bottom-up" decoding cycle (Field, 2008; Vandergrift, 2003). By focusing so hard on identifying every individual sound and word as they occur, their mental resources are entirely consumed by the present moment. Consequently, they lack the remaining "cognitive bandwidth" to look ahead and anticipate what is coming next, resulting in a breakdown in comprehension as the speed of natural speech outpaces their ability to decode it (Vandergrift and Goh, 2012).
While traditional prediction activities serve a foundational role in the language classroom, they are often insufficient for the demands of real-time communication because they focus primarily on "macro-level" preparation rather than "micro-level" processing. These traditional methods typically occur before listening, requiring a conscious, deliberate effort to activate background knowledge. While this helps orient the student, it does little to assist with the subconscious flow of speech once the audio begins (Field, 2008). In contrast, by shifting the focus toward spontaneous prediction which happens during every second of the listening process, we can help learners focus on immediate cues like specific words, stance, and transitions. By training the "proactive brain" to pre-activate expected vocabulary, we allow students to maintain engagement and fluency even when faced with complex, fast-paced input.
My Classroom Practice
In my classroom teaching, I organize the listening activities from a reverse order of 3 prediction layers. I usually start with semantic level activities, then syntactic and finally phonological level ones. These activities are used to bridge the gap between passive hearing and the active, real-time engagement with the listening material. By strategically pausing authentic audio, I force my students to shift from simply decoding sounds to actively constructing meaning.
Cliffhanger Activity
I typically select a 1- to 3-minute clip from an intellectually stimulating lecture, usually a TED Talk, specifically looking for "pivot points." These are moments where a speaker uses a discourse marker like "consequently," "on the other hand," or "it follows that" to signal a change in logical direction. I play the clip and pause it abruptly mid-sentence, right after the transition word. For example: "The data suggests a trend toward urban living, as you can see here, however this doesn’t contradict what I said earlier…" [Pause].
At this point, I task my students with predicting the functional category of the upcoming information. I explain that they do not need to guess the exact words; instead, they must determine the speaker's logic: Is the next segment a contradiction, a supporting example, or a shift in stance? To deepen this reflection, I encourage them to ask themselves: "If I were the speaker in this situation, what example or explanation would I use next? How would I construct my argument to support my stance or dispute the opposite side?"
Sometimes, I take this a step further by intentionally distracting students from the literal meaning of the words. I ask them to ignore the vocabulary entirely and focus solely on the speaker’s intonation and tone. By stripping away the text, I challenge them to guess the speaker’s stance based on the "music" of their speech. After we resume the audio, I lead a discussion not just on whether they were "correct," but on which linguistic and paralinguistic cues such as pitch, speed, or specific transition marker informed their predictions. This process transforms listening from a passive reception of data into a proactive, empathetic reconstruction of the speaker’s thought process. The following is a technological approach I used in my ESAP class.
Phonetic Forecasting
This is an activity that I use very often in my Year 2 ESAP classroom, but it could also work well for low-level students in Year 1. In my ESAP classroom, I use a specialized technique called "Acoustic Filtering" to help students master phonological prediction. To move their focus away from individual words and toward the "musicality" of academic English, I use a Low-Pass Filter in the audio editing software called Audacity to strip away the consonants and lexical details. Much like Camtasia is used for video, Audacity is a free, open-source digital audio editor that allows for precise manipulation of sound waves, but with the function of Low-Pass Filter to alter the audio and achieve the desired muffled sound effect. In order to leave behind only the low-frequency "hum" of the speaker’s vowels and rhythm, usually all frequencies above 1000 Hz need to be cut out. This creates an effect similar to hearing a lecture through a thick wall. While the specific words are unintelligible, the intonation contours and sentence stress remain clearly audible.
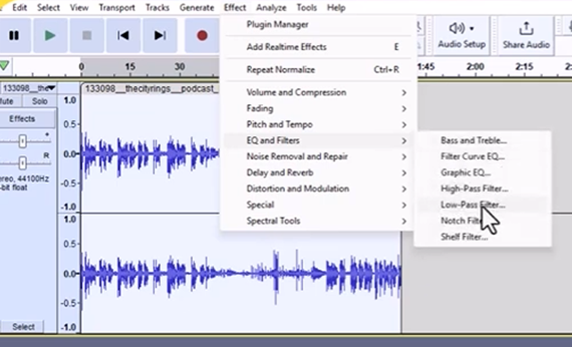
These filtered clips then can be used to challenge the students to "hum" the rhythm of a sentence and predict where the tonic stress, which is usually the most important information, will fall and how uncertain the speaker sounds when using a rising intonation. This activity is deeply rooted in Field’s theory (2008) that the "acoustic envelope" or the global sound of a phrase is often more critical for recognition than individual phonemes. By forcing students to predict the speaker’s stance or the end of a sentence based purely on pitch and tempo, teachers can train students to filter out the "noise" of function words. As Goh (2000) suggests, this helps manage the density of academic speech, allowing students to "prime" their ears for content-heavy words and reducing the cognitive strain of trying to treat every sound with equal importance.
My classroom observations and student in-class feedback revealed a common struggle: many learners were "trapped" in a word-by-word listening style. They tried to catch every single lexical cue to help them decode something in listening, which became incredibly stressful and exhausting when dealing with long and complex academic arguments. This was especially true for my lower-level students, who often felt they had to understand everything in order to understand anything.
However, once we started using this phonetic forecasting approach, the atmosphere shifted. My students reported feeling much more "confident" and "comfortable" to navigate difficult listening even when they couldn't catch every word. As one student put it: "Even when the words are gone, I can still at least tell the speaker’s emotions through the pitch and tone. It allows me to guess where a complex argument is going rather than feeling defeated when I couldn’t understand some words and giving up halfway through."
The Grammar GPS (Syntactic Shadowing)
In my ESAP classroom, I implement another second layer of practice that moves from high-level logic to the "nuts and bolts" of the language. I call this activity "Grammar GPS," and its purpose is to train my students to use their knowledge of English syntax as a navigational tool to predict upcoming word classes.
When I lead this activity, I provide my students with a short transcript from an academic lecture fragment where I have strategically removed functionally critical words, usually the main verb following a complex subject or a noun following a specific preposition. Before we even listen to the audio, I ask them to perform "Syntactic Priming." I point to a gap and ask, "Based on the surrounding structure, what part of speech must occupy this slot?" For example, if the text reads, "The primary reason for the economic shift was [_____]...", my students must identify that the grammar demands a noun or a gerund.
To put this into practice with live audio, I play a recording at a slightly reduced speed (0.75x) and perform what I call an "Echo Pause." I pause the clip the millisecond before a predictable syntactic completion. If the speaker says, "Despite the overwhelming..." and I pause, I expect my students to shout out categories like "evidence," "results," or "data." By focusing their attention on these "grammatical magnets," I help them realize that certain words are structurally inevitable. I even challenge them with complex academic structures, like the passive voice; I might pause after the auxiliary verb: "The results have been..." to see if they can anticipate the required past participle.
I explain to my students that this isn't just a grammar drill; it is about helping them "chunk" information together, which lowers their cognitive load. Native speakers process language faster because they have a structural expectation of what comes next (Kaan, 2014). If my students expect a noun after an adjective and hear one, their brain processes that information almost instantly. Without that expectation, they are forced to "manually" decode every word, which is why they often fall behind the speaker. In my view, "Grammar GPS" transforms syntax from a dry set of rules into a survival skill for the ears. I often tell my students: "Your ears are for the sounds, but your brain’s grammar is for the timing." By helping them master syntactic prediction, I am giving them the ability to "time" their listening and to allow the grammar to become automatic so they can focus on the complex ideas being presented.
Pedagogical Benefits
The most significant benefit I have observed from my teaching practice is a marked improvement in how students grasp and utilize a speaker’s core arguments. Because they are no longer exhausted by "bottom-up" decoding, they have the mental clarity to map out the speaker's logic. This becomes most evident in subsequent unscripted seminar discussions. I conduct these sessions as collaborative, spontaneous dialogues where students must respond to a discussion topic related to what they have heard. I have noted that students are able to understand a sophisticated stance much better in the audio and,more importantly, they can integrate these arguments more effectively in their own discussions. By training the "prediction engine," the "processing lag" that listeners encountered and often got silenced by can be significantly shortened. When they have the following conversation, they show greater confidence and engagement, using the speaker's own logical pivots as springboards for their own contributions to the discussion.
Implementation Challenges
Despite the clear cognitive advantages of this approach, there are two primary challenges when transitioning from theory to classroom practice. The first is the technical and logistical demand placed on the teacher. Phonetic Forecasting and Grammar GPS require meticulous preparation; the teacher must not only master audio-editing software to create filtered tracks but also possess a "surgical" precision when pausing live audio. An ill-timed pause will miss a discourse marker by half a second or stop before the syntactic cue is established. This will cause the activity to lose its predictive power. The second challenge is the psychological barrier and the resulting frustration for the students. Many L2 learners have spent years being assessed on their ability to decode every individual word; consequently, they often view spontaneous prediction with anxiety and fear that an "incorrect" guess equals a failure in comprehension. To manage this, I treat prediction as an iterative process. When students get stuck or frustrated, I offer a "second pass" with a scaffolding hint, such as identifying the speaker's tone or providing the first letter of the expected word to nudge the "prediction engine" without giving away the answer. I emphasize that an incorrect prediction is not a mistake, but a successful recalibration of their mental model.
Conclusion
In conclusion, transitioning from traditional macro-level pre-listening to a spontaneous prediction model can effectively addresses the cognitive "listening gap" by transforming the brain into a proactive prediction engine. By training students to anticipate linguistic and logical cues in real-time, these activities reduce the labor-intensive burden of bottom-up decoding and allow for more efficient processing of complex academic input. However, in classroom setting this approach is highly dependent on teacher-led scaffolding and the technical preparation of materials, which may hinder students' ability to replicate these strategies independently. In addition, applying spontaneous prediction can occasionally increase affective barriers for anxious learners. Future research could therefore investigate the transfer of these skills to autonomous listening environments and explore the integration of AI-driven tools to provide personalized, real-time predictive cues. By further examining the correlation between metacognitive awareness and predictive accuracy, we can refine these pedagogical interventions to better support the diverse processing needs of the modern L2 learner.
References
Bar, M. (2009). The proactive brain: Memory for predictions. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1521), 1235–1243. https://doi.org/10.1098/rstb.2008.0310
Field, J. (2008). Listening in the language classroom. Cambridge University Press.
Goh, C. C. (2000). A cognitive perspective on language learners' listening comprehension problems. System, 28(1), 55–75. https://doi.org/10.1016/S0346-251X(99)00060-3
Kaan, E. (2014). Predictive sentence processing in L2 and L1. Linguistic Approaches to Bilingualism, 4(3), 257–290. https://doi.org/10.1025/lab.4.3.01kaa
Vandergrift, L. (2003). From prediction through reflection: Guiding students through the process of L2 listening. Language Learning Journal, 28(1), 30–40. https://doi.org/10.1080/09571730385200201
Vandergrift, L., & Goh, C. C. (2012). Teaching and learning second language listening: Metacognition in action. Routledge.
.png)
